Quando si parla di behavioral economics, il riferimento va quasi inevitabilmente al XX secolo: Kahneman, Tversky, Thaler, Simon. Eppure, molto prima della formalizzazione matematica dei bias cognitivi e delle deviazioni dalla razionalità standard, Adam Smith aveva già offerto una teoria sorprendentemente sofisticata del comportamento umano. The Theory of Moral Sentiments non è soltanto un trattato di filosofia morale: è un’analisi psicologica profonda delle motivazioni, delle distorsioni cognitive e dei meccanismi sociali che guidano le decisioni.
Smith parte da un assunto che oggi potremmo definire anti-homo oeconomicus. L’individuo non è un calcolatore isolato che massimizza utilità in modo freddo e coerente. È un essere sociale che desidera approvazione, teme la disapprovazione e valuta continuamente se stesso attraverso lo sguardo degli altri. La famosa figura dello “spettatore imparziale” rappresenta una teoria precoce dell’internalizzazione delle norme: gli individui regolano il proprio comportamento non solo in risposta a incentivi esterni, ma attraverso un meccanismo di autocontrollo che incorpora il giudizio sociale.
Questa struttura psicologica implica già una forma di razionalità limitata. Il giudizio morale non è perfettamente oggettivo; è mediato dall’immaginazione, dalle emozioni e dalla prospettiva. Smith riconosce esplicitamente che le nostre valutazioni sono influenzate dagli esiti delle azioni anche quando, in linea di principio, dovremmo giudicare solo le intenzioni. Questa attenzione al ruolo della fortuna anticipa quello che oggi chiamiamo outcome bias o moral luck: l’esito effettivo altera la percezione della responsabilità.
Inoltre, Smith osserva che gli individui tendono sistematicamente a sopravvalutare le proprie capacità e le probabilità di successo. Parlando delle professioni ad alta incertezza e delle lotterie, descrive l’“over-weening conceit” con cui la maggior parte delle persone valuta se stessa. È una descrizione straordinariamente chiara dell’overconfidence bias. Gli individui non calcolano in modo neutrale le probabilità; sono inclini a un ottimismo irrealistico che li spinge ad assumere rischi eccessivi.
La sua analisi delle emozioni suggerisce anche un’asimmetria tra dolore e piacere. Smith riconosce che il dolore è più pungente e più incisivo del piacere, e che la sofferenza ha un impatto psicologico più profondo. Pur non formalizzando una funzione di valore come farà la prospect theory, coglie chiaramente l’idea che perdite e guadagni non siano simmetrici dal punto di vista psicologico.
Un altro elemento centrale è l’autoinganno. Smith dedica pagine notevoli alla tendenza degli individui a reinterpretare le proprie azioni per preservare un’immagine morale positiva. Questo meccanismo anticipa concetti come il self-serving bias e il motivated reasoning. Gli individui non sono solo soggetti a errori casuali: sono sistematicamente inclini a distorcere il giudizio quando è in gioco la propria reputazione interiore.
Anche la dimensione dello status occupa un posto cruciale nella sua analisi. Smith osserva che l’ammirazione per i ricchi e i potenti e il desiderio di distinzione sociale influenzano profondamente le scelte economiche. La ricerca di approvazione e superiorità simbolica altera la percezione dei costi e dei benefici. In termini moderni, le preferenze non sono puramente su consumo e reddito, ma su posizione relativa e riconoscimento sociale.
Infine, Smith riconosce esplicitamente i problemi di autocontrollo. Le passioni immediate possono entrare in conflitto con il giudizio riflessivo, e la virtù consiste nel dominare gli impulsi momentanei. Questa tensione tra impulso e controllo prefigura i modelli contemporanei a doppio sistema e le teorie della self-control failure.
Ciò che rende straordinaria la posizione di Smith è che tutti questi elementi sono integrati in una teoria coerente dell’interazione sociale. Le decisioni individuali non sono semplicemente scelte sotto vincoli; sono atti compiuti sotto uno sguardo reale o immaginato. L’economia, per Smith, non può essere separata dalla psicologia morale.
La behavioral economics moderna ha formalizzato questi meccanismi, li ha misurati sperimentalmente e li ha inseriti in modelli matematici. Ma l’intuizione di fondo — che l’essere umano è sistematicamente soggetto a bias, guidato da emozioni e profondamente inserito in una rete di norme sociali — era già presente con straordinaria chiarezza nel XVIII secolo.
Rileggere Adam Smith in questa prospettiva significa riconoscere che la behavioral economics non rappresenta una rottura radicale con la tradizione classica, ma in molti aspetti un ritorno alle sue radici più profonde.
Quando Adam Smith viene evocato nel dibattito pubblico, il riferimento quasi automatico è alla Wealth of Nations e alla “mano invisibile”. Eppure la sua architettura teorica non può essere compresa senza The Theory of Moral Sentiments (1759; ed. definitiva 1790). È qui che Smith sviluppa la sua antropologia morale: una teoria dell’uomo come essere intrinsecamente sociale, bisognoso di riconoscimento e capace di autocontrollo.
Lungi dall’essere un’opera separata, la Theory fornisce il fondamento normativo e psicologico della teoria economica smithiana.
La simpatia come fondamento della moralità
Il libro si apre con una frase tra le più celebri dell’intera storia della filosofia morale:
“How selfish soever man may be supposed, there are evidently some principles in his nature, which interest him in the fortune of others.”
Per quanto egoista possa essere considerato l’uomo, esistono principi nella sua natura che lo rendono interessato alla sorte degli altri.
Questo è il punto di partenza. La “sympathy” smithiana non è mera compassione. È la capacità di immaginare noi stessi nella situazione altrui. Non percepiamo direttamente i sentimenti degli altri; li comprendiamo trasponendoci, con l’immaginazione, nel loro caso:
“As we have no immediate experience of what other men feel, we can form no idea of the manner in which they are affected, but by conceiving what we ourselves should feel in the like situation.”
La moralità nasce quindi da un confronto intersoggettivo. Giudichiamo appropriata un’emozione quando riusciamo a condividerla; la disapproviamo quando la percepiamo come sproporzionata. In questo senso, l’approvazione morale coincide con la simpatia riuscita.
Lo spettatore imparziale e la nascita della coscienza
Il contributo teorico più originale dell’opera è la figura dello “impartialspectator”. Vivendo in società, impariamo a guardarci con gli occhi degli altri. Interiorizziamo uno sguardo ideale, equo e informato, che giudica le nostre passioni. Smith scrive:
“We endeavour to examine our own conduct as we imagine any other fair and impartial spectator would examine it.”
Cerchiamo di esaminare la nostra condotta come immaginiamo che la esaminerebbe qualsiasi altro osservatore equo e imparziale.
Questa interiorizzazione è il fondamento della coscienza morale. Non agiamo bene soltanto per essere lodati, ma per essere degni di lode. Smith distingue in modo sottile tra “love of praise” e “love of praise-worthiness”.
L’individuo maturo non cerca solo approvazione effettiva; desidera che essa sia giustificata. Questa intuizione è cruciale per l’economia: gli agenti non sono mossi esclusivamente da incentivi materiali, ma anche dal bisogno di riconoscimento e coerenza morale.
Giustizia, beneficenza e ordine sociale
Nella Parte II Smith distingue tra giustizia e beneficenza. La giustizia è la virtù minima e indispensabile: consiste nel non nuocere agli altri. È coercibile. Senza giustizia, la società collassa.
“Beneficence is always free, it cannot be extorted by force.”
La beneficenza è lodevole ma non può essere imposta. Possiamo ammirarla, ma non punire la sua assenza. Questa distinzione è fondamentale per comprendere la teoria delle istituzioni. Il mercato presuppone un quadro di giustizia stabile. Ma la qualità della vita sociale dipende anche da virtù non coercibili: fiducia, reciprocità, senso dell’onore.
Autocontrollo e virtù
Smith non propone un sentimentalismo indulgente. La moralità richiede disciplina delle passioni. L’ideale della virtù è l’equilibrio tra sensibilità e autocontrollo.
“Self-command” è la capacità di moderare le proprie emozioni per renderle compatibili con ciò che lo spettatore imparziale può approvare. Nella celebre formulazione:
“To feel much for others and little for ourselves… constitutes the perfection of human nature.”
La perfezione morale non consiste nell’annullare l’interesse personale, ma nel ridimensionarlo alla luce di una prospettiva più ampia.
La paura della morte e il fondamento dell’ordine
Un passaggio spesso citato mostra la profondità psicologica dell’analisi smithiana. Riflettendo sulla nostra tendenza a immaginare la condizione dei morti, Smith osserva che il terrore della morte nasce da un’illusione dell’immaginazione. E conclude:
“The dread of death… is the great poison to the happiness, but the great restraint upon the injustice of mankind.”
La paura della morte è un veleno per la felicità individuale, ma anche un freno potente contro l’ingiustizia. Qui emerge una concezione realistica dell’ordine sociale: le passioni umane sono ambivalenti, ma contribuiscono alla stabilità delle istituzioni.
Influenza della fortuna e giudizio morale
Smith analizza inoltre l’influenza degli esiti sui giudizi morali. Pur sapendo che le intenzioni dovrebbero essere centrali, tendiamo a giudicare più severamente quando le conseguenze sono gravi. Questo tema, oggi noto come “moral luck”, mostra l’acutezza empirica della sua teoria. La morale non è un sistema astratto perfettamente coerente, ma una pratica sociale soggetta a limiti cognitivi.
Il legame con la Wealth of Nations
La celebre frase della Wealth of Nations secondo cui non ci aspettiamo il nostro pranzo dalla benevolenza del macellaio, ma dal suo interesse, non implica una concezione riduttivamente egoistica dell’uomo. Presuppone invece un contesto in cui gli individui rispettano norme, cercano reputazione e temono la disapprovazione. L’essere umano smithiano è un agente che desidera approvazione e teme il giudizio morale. Il mercato funziona perché gli individui operano sotto lo sguardo reale e immaginario degli altri.
Conclusione
The Theory of Moral Sentiments propone una visione dell’economia come scienza morale. L’uomo non è un calcolatore isolato, ma un essere che vive di riconoscimento reciproco, di simpatia e di autocontrollo. Smith ci ricorda che l’ordine economico non poggia solo su incentivi e prezzi, ma su un delicato equilibrio tra interesse personale e desiderio di essere degni dello sguardo dello spettatore imparziale. Rileggere Smith alla luce della sua teoria morale significa recuperare una concezione più ricca dell’economia: non solo analisi dei mercati, ma studio delle motivazioni, delle norme e delle istituzioni che rendono possibile la cooperazione sociale.
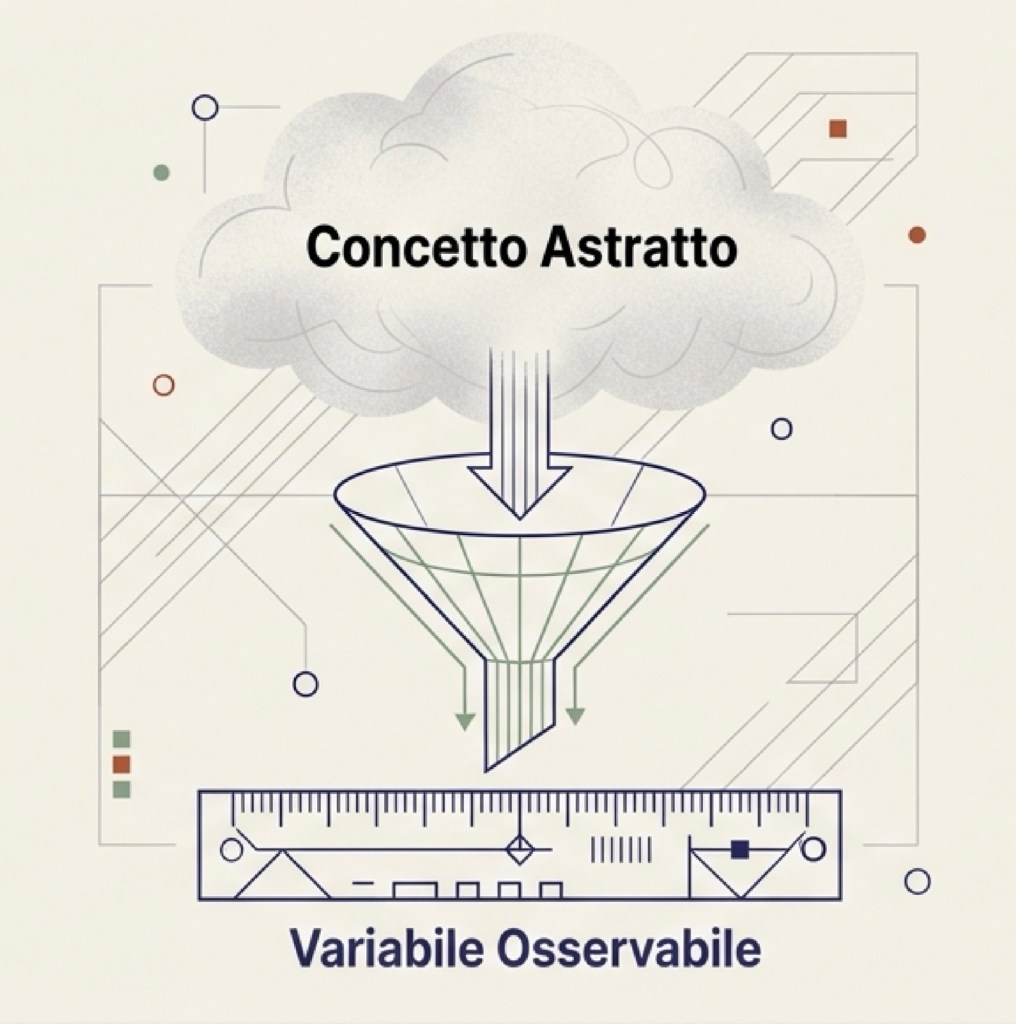
Quando vogliamo capire un fenomeno sociale o economico — per esempio migrazione, diseguaglianza, povertà o cambiamento climatico — la prima cosa da fare è chiarire che cosa stiamo cercando di capire. Sembra banale, ma non lo è. Dire “voglio studiare la povertà” non basta, perché “povertà” può significare molte cose: può essere un reddito sotto una certa soglia, può essere l’assenza di beni essenziali, può essere una condizione di deprivazione che riguarda salute, istruzione, casa. Lo stesso vale per “migrazione” o “cambiamento climatico”: dobbiamo decidere quale aspetto misuriamo, con quale unità, in quale periodo, in quali luoghi. Finché non definiamo l’oggetto in modo osservabile e misurabile, non abbiamo ancora un problema empirico testabile: abbiamo un tema (o una domanda generale), ma non ancora una strategia per metterlo alla prova con i dati.
Misurare significa raccogliere dati (e trasformare informazioni in variabili)
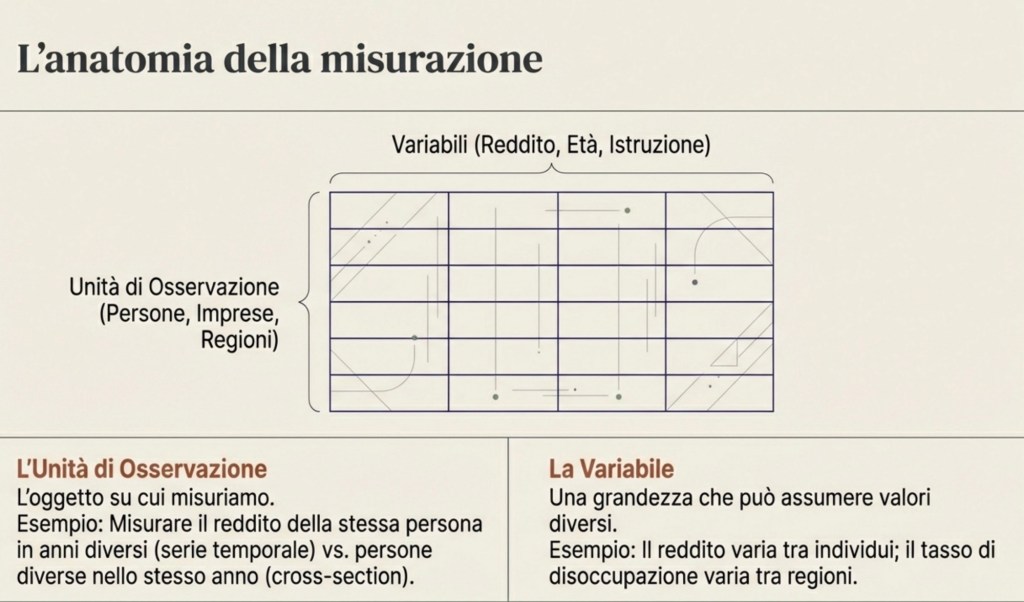
Misurare significa raccogliere dati. I dati sono informazioni associate a unità di osservazione. Spesso sono numeri (reddito, età, temperatura), ma possono anche essere categorie (occupato/disoccupato, titolo di studio, partito votato) o persino testi (risposte aperte, post, articoli): per fare analisi quantitativa, queste informazioni vengono in genere codificate in variabili utilizzabili.
L’unità di osservazione può essere una persona, una famiglia, un’impresa, un comune, una regione, un paese. Se misuro il reddito di una persona in un certo anno, sto facendo un’osservazione. Se misuro il reddito di molte persone nello stesso anno, ottengo un insieme di osservazioni. Se misuro il reddito della stessa persona in anni diversi, ottengo una serie di osservazioni nel tempo. Se misuro il reddito di persone diverse in luoghi diversi e anni diversi, ottengo un insieme ancora più ricco.
Una volta raccolti i dati, succede quasi sempre una cosa: i valori non sono tutti uguali. Cambiano tra persone, tra territori, tra anni. Proprio perché cambiano, diciamo che stiamo osservando una variabile. Una variabile è una grandezza che può assumere valori diversi. Il reddito è una variabile perché varia tra individui e nel tempo. Il tasso di disoccupazione è una variabile perché cambia tra regioni e tra periodi. La temperatura media è una variabile perché cambia nel tempo e nello spazio. Anche gli anni di istruzione sono una variabile, perché non tutti studiano lo stesso numero di anni.
Misurare e descrivere non è ancora spiegare
A questo punto abbiamo fatto un passo fondamentale: abbiamo trasformato un fenomeno in qualcosa di misurabile. Ma misurare e descrivere non è ancora spiegare. La domanda successiva è: perché osserviamo questa variazione? Perché alcune persone hanno redditi più alti di altre? Perché alcune regioni sono più povere? Perché alcuni paesi emettono più CO₂?
Quando chiediamo “perché”, stiamo entrando nel territorio delle spiegazioni, e quindi dei modelli.
Che cos’è un modello (e cosa non è)
Un modello economico è un modo di scrivere un’ipotesi in forma precisa. Non è la realtà, e non è “la verità”. È una rappresentazione semplificata che serve a ragionare in modo rigoroso. Il modello ci obbliga a essere chiari: quali variabili contano, e quale relazione immaginiamo tra loro.
Se pensiamo che il reddito dipenda dall’istruzione, possiamo chiamare il reddito Y e l’istruzione X e dire che Y è funzione di X, cioè Y = f(X). Questa frase significa: l’istruzione è una possibile causa o determinante del reddito. Ma, ed è essenziale capirlo, questa è un’ipotesi di lavoro. Non è ancora una conclusione.
Dati e grafici: vedere un’associazione
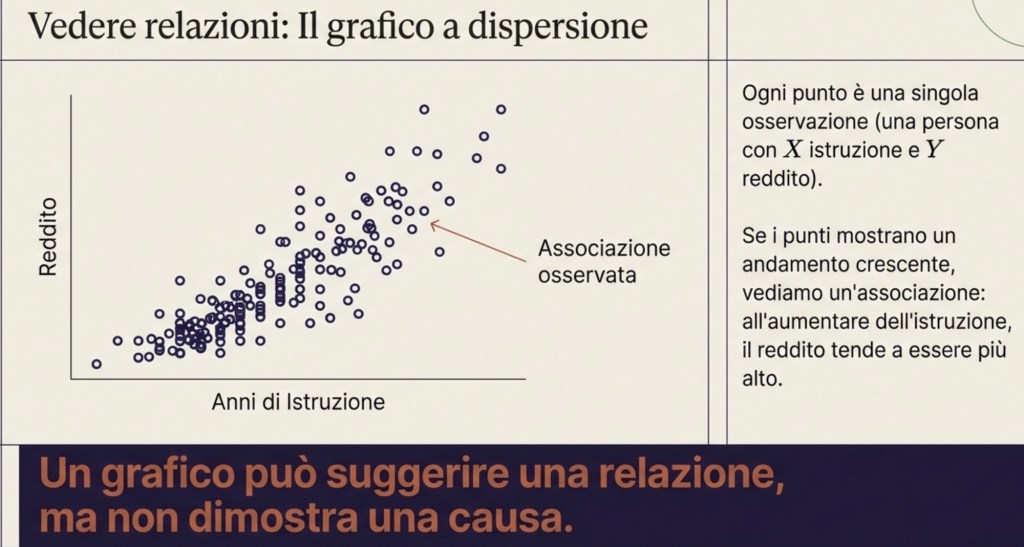
Per vedere se l’ipotesi è compatibile con i dati, possiamo iniziare con una rappresentazione semplice: un grafico cartesiano. Mettiamo gli anni di istruzione sull’asse orizzontale e il reddito sull’asse verticale. Ogni punto del grafico rappresenta una singola osservazione: una persona in un certo luogo e in un certo momento, con un certo numero di anni di istruzione e un certo reddito.
Se i punti sono sparsi a caso, senza forma, allora non vediamo una relazione sistematica. Se invece i punti mostrano un andamento, per esempio crescente, allora vediamo un’associazione: all’aumentare dell’istruzione, il reddito tende a essere più alto.
Associazione ≠ causalità: la distinzione centrale
Questa è una scoperta? È un’informazione importante, ma non è ancora una conclusione causale. Qui entra la distinzione più importante di tutta l’economia empirica: associazione non significa causalità.
Dire che due variabili sono associate significa dire che si muovono insieme nei dati. Dire che una variabile causa l’altra significa qualcosa di più forte: significa che se intervenissimo sul mondo e cambiassimo X, allora Y cambierebbe come conseguenza di questo cambiamento.
Perché non possiamo passare direttamente da “si muovono insieme” a “una causa l’altra”?
Perché esistono spiegazioni alternative che producono lo stesso andamento nei dati.
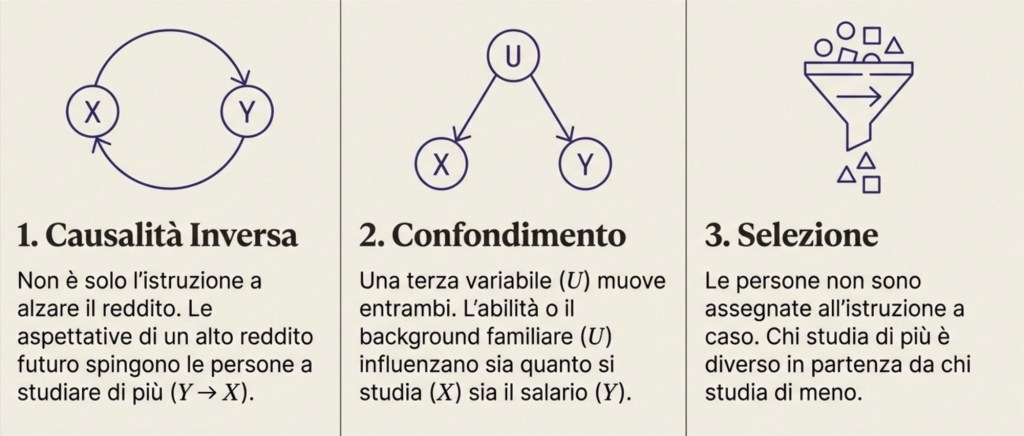
(1) Causalità inversa (reverse causality). Può essere che non sia (solo) X a influenzare Y, ma anche il contrario. Un esempio più chiaro, nel caso istruzione–reddito, è questo: le persone scelgono quanta istruzione fare anche in base alle aspettative sul rendimento futuro (opportunità di carriera, salari attesi). In questo senso, un “reddito atteso” o le prospettive economiche (legate a Y) possono influenzare la scelta di X.
(2) Confondimento (confounding). Esiste una terza variabile che influenza sia l’istruzione sia il reddito. Chiamiamola U. U potrebbe essere abilità, motivazione, salute, qualità della scuola, ambiente familiare, risorse dei genitori. Se U spinge una persona a studiare di più e, indipendentemente, la rende anche più produttiva e quindi più pagata, allora istruzione e reddito appaiono legati anche se una parte del legame non è l’effetto dell’istruzione, ma l’effetto comune di U su entrambe.
(3) Selezione (selection). Le persone non ricevono istruzione a caso. Studiano di più o di meno per vincoli, scelte, opportunità. Se chi studia di più è diverso da chi studia di meno già prima (per caratteristiche osservate o non osservate), allora confrontare i due gruppi non equivale a isolare l’effetto dell’istruzione.
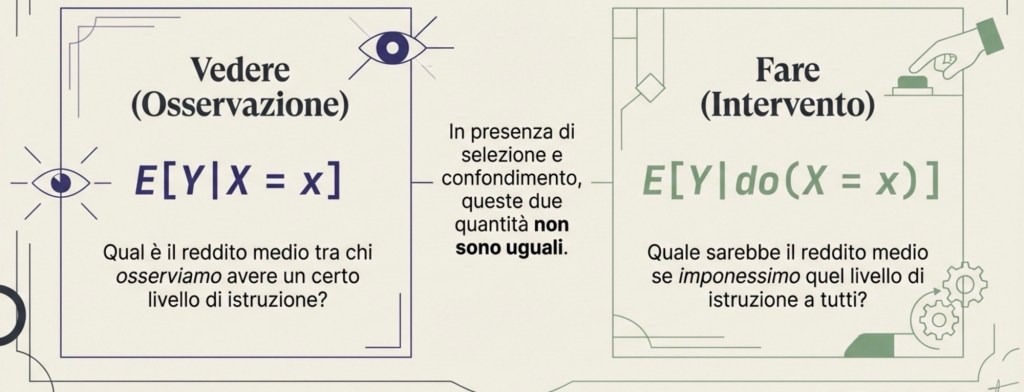
Intervento vs osservazione: la logica di Pearl (do-notation)
Questo modo di ragionare è stato reso estremamente chiaro da Judea Pearl, che insiste su un punto: la causalità riguarda gli interventi, non solo le osservazioni.
Osservare X = x significa guardare chi ha un certo livello di istruzione; ma queste persone possono essere diverse per molte caratteristiche. Intervenire su X significa fissare dall’esterno il livello di istruzione, come se potessimo “impostare” X, e poi vedere cosa succede a Y. Pearl usa la notazione do(X = x) per indicare un intervento.
A questo punto serve anche una piccola nota di notazione:
E[·] indica il valore atteso, che qui possiamo leggere come “media”.
La differenza è decisiva:
E[Y | X = x] è la media di Y tra chi osserviamo avere X = x; E[Y | do(X = x)] è la media che avremmo se imponessimo X = x (cioè se facessimo un intervento).
In generale non sono la stessa cosa, proprio a causa di selezione e confondimento.
In sintesi: osservare “chi ha X = x” non equivale a “imporre X = x”.
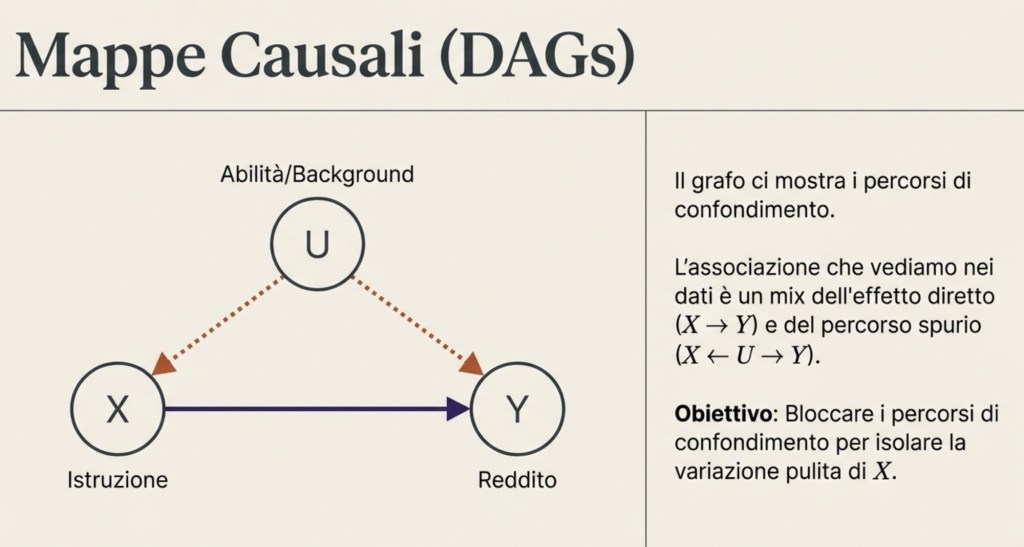
Grafi causali: visualizzare confondimento e percorsi
Per essere più concreti, possiamo rappresentare le ipotesi causali con grafi fatti di variabili e frecce.
Se crediamo che l’istruzione influenzi il reddito, disegniamo una freccia da X → Y. Se crediamo che una variabile U influenzi sia l’istruzione sia il reddito, disegniamo U → X e U → Y.
Questo disegno serve a capire quali sono i percorsi attraverso cui X e Y risultano collegati nei dati. Il compito dell’analisi causale è bloccare i percorsi di confondimento, cioè fare in modo che la variazione in X che utilizziamo per stimare l’effetto su Y non sia contaminata da U.
La regressione: quantificare un’associazione (non “creare” causalità)
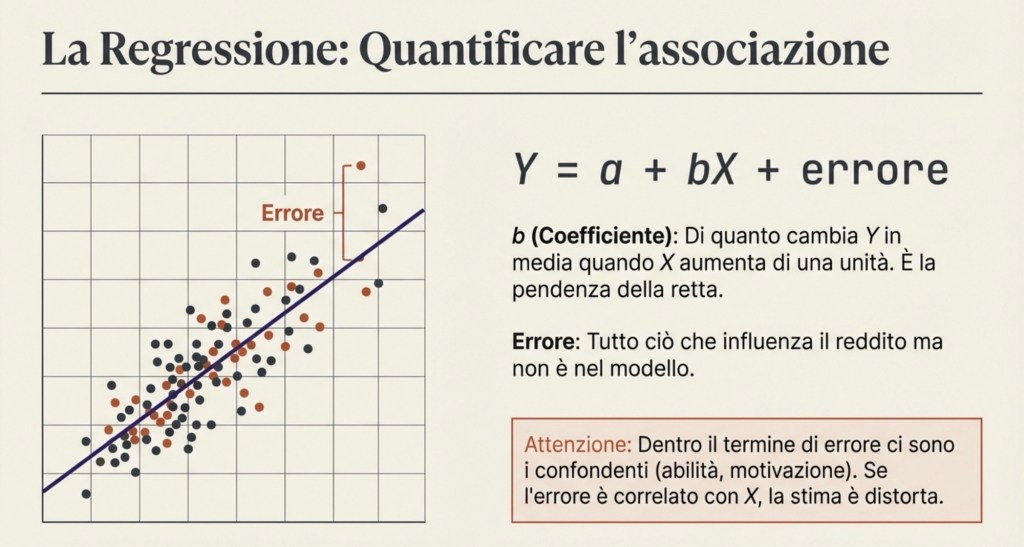
A questo punto entra uno strumento quantitativo fondamentale: la regressione. La regressione lineare stimata con i minimi quadrati ordinari (OLS) è un modo per riassumere in numeri l’andamento che vediamo nei dati. Nella forma più semplice, scriviamo il reddito come una costante più un coefficiente moltiplicato per l’istruzione, più un termine di errore:
Y = a + bX + errore
Il coefficiente davanti a X descrive di quanto cambia Y, in media, quando X aumenta di una unità, secondo la migliore approssimazione lineare dei dati. OLS sceglie quel coefficiente in modo da rendere piccoli, nel complesso, gli scarti tra i valori osservati del reddito e i valori che la retta “predice”. In altre parole, disegna la retta che meglio attraversa la nuvola di punti.
È fondamentale capire il ruolo del termine di errore. Non è un semplice dettaglio tecnico. Dentro l’errore c’è tutto ciò che influenza il reddito e che non abbiamo incluso esplicitamente nel modello: abilità, motivazione, salute, contesto familiare, condizioni locali, e così via. Se questi fattori sono correlati con l’istruzione, il coefficiente stimato mescola l’effetto dell’istruzione con l’effetto dei confondenti. Per questo una regressione semplice descrive un’associazione, ma non diventa automaticamente causale.
In sintesi: la regressione riassume “come stanno insieme” X e Y nei dati; la causalità dipende dal disegno.
Regressioni con controlli: cosa significa “a parità delle altre variabili”
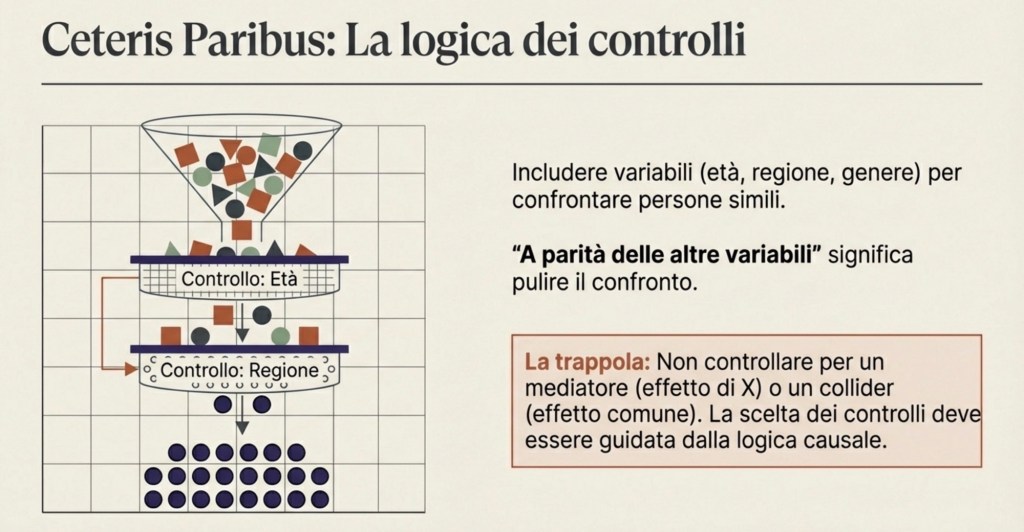
Per ridurre il confondimento, si usano regressioni con controlli. In una regressione con controlli includiamo altre variabili, come età, genere, regione, istruzione dei genitori, esperienza lavorativa.
Che cosa significa “controllare” in modo preciso? Significa confrontare persone che hanno gli stessi valori dei controlli. Quando diciamo che il coefficiente dell’istruzione è stimato “a parità delle altre variabili”, stiamo dicendo: stiamo confrontando persone simili rispetto ai controlli inclusi, e dentro questo confronto stimiamo l’associazione tra istruzione e reddito. Questo è il significato concreto di ceteris paribus.
Ma anche qui bisogna essere rigorosi: “a parità delle altre variabili” significa a parità delle variabili che abbiamo incluso, non a parità di tutto ciò che esiste nel mondo. Se esistono confondenti non osservati che restano fuori, il problema può rimanere.
Inoltre, controllare non è sempre una buona idea: se controlliamo per una variabile che è un effetto dell’istruzione (un mediatore), rischiamo di “togliere” parte dell’effetto che vogliamo misurare; se controlliamo per una variabile influenzata sia da X sia da Y (un caso tipico di collider), possiamo introdurre nuove distorsioni.
Per questo la scelta di cosa controllare deve essere guidata da una chiara idea causale, non da un automatismo.
In sintesi: i controlli aiutano solo se scelti con logica causale; altrimenti possono peggiorare.
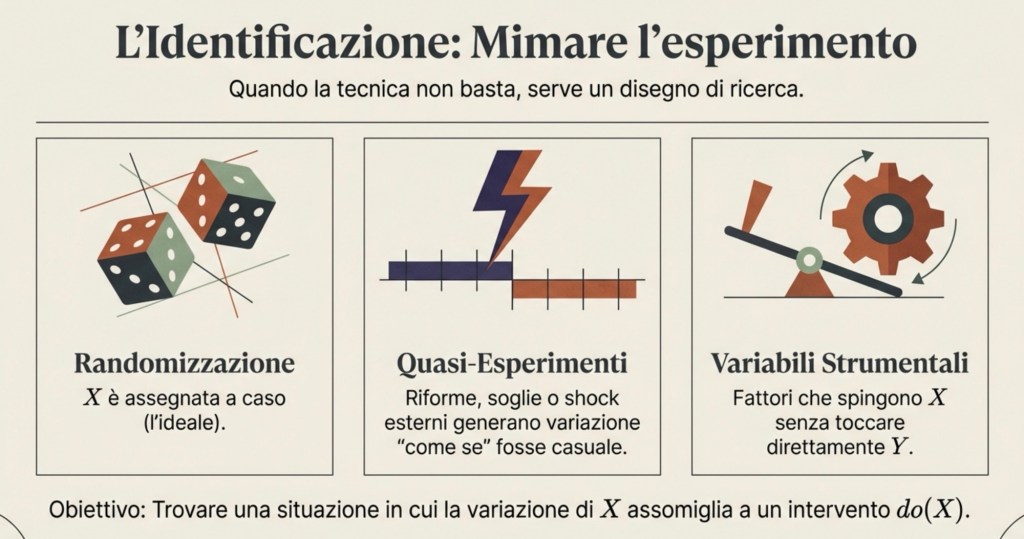
Identificazione: quando la variazione in X assomiglia a un intervento
Come fa allora uno scienziato a stimare un effetto causale in modo credibile? L’idea generale è creare, o sfruttare, una situazione in cui la variazione di X sia equivalente a un intervento, cioè assomigli a do(X).
Il caso più pulito è la randomizzazione: se X viene assegnata a caso, allora non è correlata ai confondenti, e il confronto tra gruppi con X diversa identifica un effetto causale. Quando la randomizzazione non è possibile, si cercano quasi-esperimenti: regole, riforme, soglie, lotterie, shock esterni che generano variazione in X indipendente dai confondenti. In altri casi si usano strumenti: variabili che spingono X ma non influenzano Y se non attraverso X e non sono legate ai confondenti.
In tutti questi casi, la regressione può essere usata per quantificare l’effetto, ma il punto centrale rimane il disegno che rende credibile l’interpretazione causale.
In sintesi: la tecnica (regressione) non basta; serve un disegno che renda plausibile “come se fosse un intervento”.
Incertezza: perché anche le buone stime non sono perfette
Fin qui abbiamo parlato di causalità e di metodi. Ora dobbiamo aggiungere un altro pezzo indispensabile: l’incertezza. Anche quando il disegno è corretto, le stime non sono perfette perché i dati contengono rumore e perché spesso osserviamo solo un campione. Qui entra la probabilità.
La probabilità, in questo contesto, serve a descrivere che cosa succederebbe se ripetessimo lo stesso studio molte volte. Se prendiamo un campione di individui e stimiamo un coefficiente, quel coefficiente dipende dal campione specifico. Se prendessimo un altro campione, otterremmo un numero leggermente diverso. Questa variabilità tra campioni è inevitabile. L’inferenza statistica serve a misurarla.
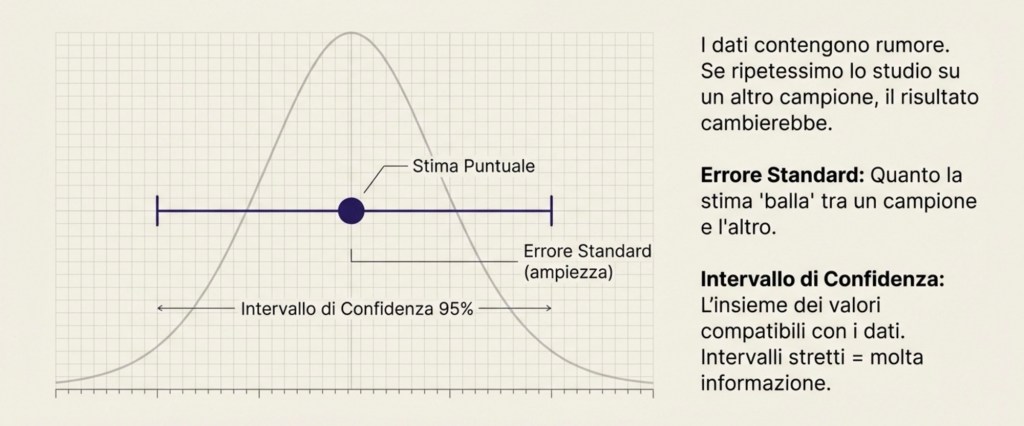
Errori standard e intervalli di confidenza
Il modo più comune per descrivere la precisione di una stima è l’errore standard: una misura di quanto la nostra stima cambierebbe se ripetessimo l’analisi su campioni diversi. Se l’errore standard è piccolo, la stima è precisa; se è grande, la stima è imprecisa. L’errore standard dipende dalla dimensione del campione, dal rumore nei dati e da quanta variazione utile abbiamo in X.
Un modo molto chiaro per comunicare precisione è l’intervallo di confidenza. Un intervallo di confidenza al 95% è costruito in modo tale che, se ripetessimo lo studio moltissime volte e costruissimo ogni volta lo stesso tipo di intervallo, nel 95% dei casi l’intervallo conterrebbe il vero valore del parametro.
Lettura pratica: l’intervallo di confidenza ci dice quali valori del coefficiente sono compatibili con i dati, tenendo conto dell’incertezza. Intervalli stretti indicano molta informazione; intervalli larghi indicano che i dati non permettono conclusioni precise.
p-value, significatività e rilevanza
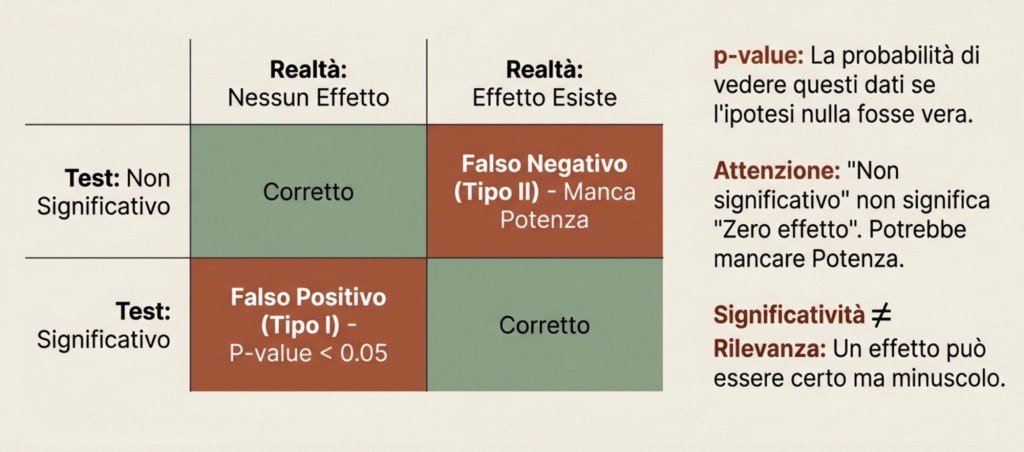
Accanto agli intervalli, spesso si usano i test di ipotesi e la significatività statistica. Il caso più comune è testare se un coefficiente è diverso da zero.
L’ipotesi nulla dice: il coefficiente è zero, quindi nel modello specificato non c’è effetto. Il test valuta quanto sarebbe raro ottenere un coefficiente almeno così grande in valore assoluto se l’effetto vero fosse davvero zero.
Questa rarità viene riassunta dal p-value. Il p-value è la probabilità di osservare un risultato almeno così estremo, assumendo che l’ipotesi nulla sia vera. Non è la probabilità che l’ipotesi nulla sia vera.
Quando un p-value è piccolo, diciamo che il risultato è “statisticamente significativo” rispetto a una soglia scelta, spesso 5%. Questo significa: se l’effetto vero fosse zero, sarebbe raro vedere un risultato come quello osservato. Ma non significa che l’effetto sia grande o importante. Significativo non vuol dire rilevante.
Errori di tipo I e II e potenza statistica
Possiamo sbagliare in due modi: concludere che c’è un effetto quando in realtà non c’è (falso positivo, errore di tipo I); non rilevare un effetto che esiste davvero (falso negativo, errore di tipo II).
La potenza statistica (power) è la probabilità che un test riesca a rilevare un effetto quando l’effetto esiste davvero. Uno studio con alta potenza ha buone probabilità di individuare un effetto reale; uno studio con bassa potenza rischia di produrre risultati “non significativi” anche quando l’effetto è presente.
Un punto importantissimo: un risultato non significativo non prova che l’effetto sia zero. Può semplicemente significare che lo studio non aveva abbastanza informazione per distinguerlo da zero.
Da cosa dipende la potenza? Dipende dalla grandezza dell’effetto, dal rumore nei dati, dalla dimensione del campione e dalla soglia di significatività scelta.
Test multipli e disciplina della ricerca
C’è una trappola comune quando si lavora con i dati: se si provano molte ipotesi, molte specificazioni, molti sottogruppi, è facile trovare qualche risultato “significativo” solo per caso. Anche se ogni singolo test ha una probabilità del 5% di produrre un falso positivo sotto l’ipotesi nulla, facendo molti test la probabilità di trovare almeno un falso positivo cresce.
Questo è il motivo per cui la ricerca empirica richiede disciplina: chiarezza su quali analisi sono principali e quali esplorative, trasparenza sulle scelte, e attenzione ai test multipli. Non perché la statistica sia fragile, ma perché l’uso non disciplinato dei test può produrre conclusioni ingannevoli.
Tirando le fila: la logica completa del metodo empirico
Si parte da un fenomeno e lo si rende misurabile. La misura produce variabili che variano tra unità, luoghi o tempi. Si osservano relazioni nei dati e si quantificano con strumenti come la regressione. Si costruisce un modello come ipotesi rigorosa sui meccanismi. Si distingue l’associazione dalla causalità e si ragiona in termini di interventi, cioè di cosa succederebbe se cambiassimo X. Si costruisce, quando possibile, un disegno che renda credibile interpretare la variazione in X come un intervento, bloccando il confondimento. Infine, si usa la probabilità per quantificare l’incertezza: errori standard e intervalli di confidenza per la precisione, p-value e test per valutare compatibilità con l’ipotesi nulla, e potenza per capire se lo studio è in grado di rilevare effetti reali.
Solo mettendo insieme questi pezzi possiamo trasformare dei numeri (e più in generale dei dati) in conoscenza affidabile, senza confondere ciò che i dati mostrano con ciò che possiamo davvero concludere.
Perché tutto questo è importante per il tuo futuro
Nella vita professionale — in un’amministrazione pubblica, in un’impresa, in una ONG, nel giornalismo, nella consulenza o nella ricerca — incontrerai continuamente affermazioni come: “questa politica riduce la povertà”, “questa riforma aumenta l’occupazione”, “questa formazione fa crescere i salari”, “questa misura ambientale funziona”. Queste sono affermazioni causali. I metodi quantitativi servono a valutare se sono fondate oppure se stanno confondendo correlazioni, selezione e confondimento. In altre parole, imparare questi strumenti significa imparare a distinguere tra un risultato convincente e una conclusione fragile: è una competenza chiave per leggere (e produrre) evidenza credibile nel mondo reale.
Mini-glossario (essenziale)
Unità di osservazione: l’oggetto su cui misuri (persona, famiglia, impresa, regione…).
Variabile: una grandezza che può assumere valori diversi (reddito, anni di istruzione, disoccupazione…).
Associazione: X e Y si muovono insieme nei dati.
Causalità: cambiare X con un intervento cambia Y.
Confondente (U): variabile che influenza sia X sia Y, “sporcando” l’associazione.
Selezione: X non è assegnata a caso; i gruppi con X diversa differiscono già “prima”. do(X=x): notazione per un intervento che impone X=x.
Regressione (OLS): metodo che stima una relazione lineare “media” tra variabili.
Errore standard: misura della variabilità della stima tra campioni.
Intervallo di confidenza: insieme di valori compatibili con i dati (con una certa regola di costruzione).
p-value: probabilità di un risultato almeno così estremo se l’ipotesi nulla fosse vera.
Potenza (power): probabilità di rilevare un effetto se l’effetto esiste davvero.
Quasi-esperimento / identificazione: situazione in cui la variazione in X è credibilmente “come se” fosse random.
C’è un dato di partenza che raramente viene messo al centro della discussione, ma che dovrebbe guidare ogni riflessione seria sull’università: oggi tra il 30 e il 50 percento di una coorte passa dall’istruzione universitaria. È un fenomeno storico, recente, e irreversibile. L’università non è più un’istituzione per pochi, e non può più essere pensata come tale. Serve alla massa, e deve farlo bene.
Questo implica un obiettivo realistico e, in fondo, nobile: dare a molti studenti strumenti sufficienti per migliorare la loro traiettoria di vita e di lavoro. Non trasformazioni radicali, ma competenze solide, linguaggi condivisi, capacità di orientamento. Se questo obiettivo è raggiunto per una larga parte degli iscritti, l’università sta già funzionando.
Eppure, accanto a questo successo quantitativo, esiste un fatto strutturale che chi insegna osserva ogni giorno: solo una piccola quota degli studenti, forse intorno al 5 percento, trae un beneficio profondo e duraturo dall’esperienza universitaria. Sono quelli che partecipano, che leggono davvero, che riflettono, che collegano i contenuti, che pongono domande non perché “servono all’esame” ma perché non possono farne a meno. Non sono necessariamente i più brillanti in senso stretto, ma quelli con fame di capire.
Il problema non è che questa distribuzione esista. Il problema è che continuiamo a fingere che non esista.
Offrire lo stesso identico percorso a tutti appare equo, ma in realtà è inefficiente su entrambi i fronti. Per la maggioranza degli studenti è spesso uno spreco di risorse: tempo, energie, opportunità che eccedono la domanda reale e che non vengono trasformate in valore. Per quel piccolo gruppo altamente motivato, invece, è un sotto-investimento sistematico. Il percorso standard li rallenta, li annoia, li costringe a muoversi sempre al di sotto delle loro possibilità.
Come funziona allora, oggi, il sistema? In modo implicito e delegato. Si lascia alla capacità individuale dello studente la creazione delle opportunità. Chi è intraprendente, sicuro, socialmente attrezzato, riesce a costruirsi esperienze extra: tesi ambiziose, periodi all’estero, contatti, progetti. Chi non lo è, resta nel percorso formale, anche quando avrebbe le potenzialità per molto di più.
Questo modello, in passato, funzionava meglio. Gli studenti erano più immersi nel mondo reale, più abituati all’interazione diretta, più allenati a chiedere, a esporsi, a rischiare un rifiuto. Oggi le nuove generazioni sono più chiuse, più virtuali, più frammentate. Anche gli studenti migliori spesso non sanno riconoscere l’occasione giusta o non riescono a prendersela. Non per mancanza di talento, ma per mancanza di capitale relazionale, di sicurezza, di pratica nel mondo non mediato.
Il paradosso è evidente: il sistema si basa sull’auto-selezione proprio nel momento storico in cui l’auto-selezione funziona peggio. Le opportunità ci sono, ma diventano invisibili o accessibili solo a chi possiede già i codici giusti. Il risultato non è meritocrazia, ma riproduzione.
Forse la vera sfida dell’università oggi non è scegliere tra élite e massa, ma accettare che servano livelli diversi di investimento. Standard solidi per molti, percorsi esplicitamente più intensi per pochi. Non come premio morale, ma come uso efficiente delle risorse e come risposta a una eterogeneità che i dati, prima ancora dell’esperienza, rendono impossibile ignorare.
Una delle idee più profonde della scienza moderna è che la natura obbedisca a leggi che possono essere espresse in forma matematica. Non si tratta solo di un modo comodo di descrivere il mondo, ma della convinzione che dietro la varietà dei fenomeni esista un ordine necessario, astratto, e in qualche senso intelligibile. Questa idea, però, non è sempre esistita. È il risultato di una lunga storia intellettuale, fatta di intuizioni, resistenze e svolte radicali.
Le prime tracce di questa visione risalgono all’antica Grecia. Nel VI secolo a.C., i pitagorici scoprono che fenomeni naturali apparentemente qualitativi, come l’armonia musicale, obbediscono a rapporti numerici semplici. La relazione tra lunghezza delle corde e intervalli sonori porta alla famosa tesi secondo cui “tutto è numero” (Aristotele, Metafisica, I, 5). È un’idea potente, ma ancora lontana dalla scienza nel senso moderno: il numero non è uno strumento di misurazione empirica, bensì il principio metafisico dell’ordine cosmico.
Con Platone, nel IV secolo a.C., la matematica assume un ruolo centrale nella conoscenza. Nel Timeo, il cosmo è costruito secondo proporzioni geometriche, e le forme matematiche rappresentano la struttura profonda del reale. La matematica è vista come il linguaggio dell’intelligibile, superiore al mondo sensibile e mutevole. Non a caso, la tradizione attribuisce all’Accademia il motto “nessuno entri qui se non conosce la geometria”. Tuttavia, anche in Platone la matematica non nasce dall’osservazione sistematica della natura, ma da una concezione filosofica dell’ordine.
Aristotele introduce una svolta decisiva, ma ambigua. Da un lato fonda la fisica come studio della natura; dall’altro separa nettamente la matematica dalla spiegazione dei fenomeni naturali. Per Aristotele, la matematica astrae dalle qualità reali e non può cogliere le cause dei processi fisici (Fisica, II, 2). La sua enorme influenza farà sì che, per secoli, la matematizzazione della natura venga vista con sospetto: utile per descrivere, ma incapace di spiegare.
Un’eccezione straordinaria è Archimede (III secolo a.C.). Nei suoi lavori sulla leva e sul galleggiamento, Archimede usa dimostrazioni matematiche per derivare leggi fisiche generali, anticipando un metodo che diventerà centrale solo molto più tardi (On Floating Bodies). Einstein lo definirà uno dei più grandi geni scientifici di tutti i tempi. Eppure, il suo approccio rimane isolato e non genera una tradizione continua.
Durante il Medioevo, la matematica viene applicata in modo sporadico allo studio del moto (si pensi ai “calculatores” di Oxford, come Thomas Bradwardine), ma l’idea che la natura sia governata universalmente da leggi matematiche non è ancora dominante. La fisica resta prevalentemente qualitativa e teleologica.
La svolta arriva tra XVI e XVII secolo, con quella che oggi chiamiamo Rivoluzione scientifica. Galileo Galilei rende esplicita una nuova concezione della natura: il mondo fisico è governato da leggi necessarie, e queste leggi sono matematiche. Nel Saggiatore (1623) scrive che “il libro della natura è scritto in caratteri matematici”, e che senza triangoli, cerchi e numeri è impossibile comprenderlo. Qui la matematica non è più una filosofia dell’ordine, ma uno strumento operativo per formulare leggi, fare previsioni e confrontarle con l’esperienza.
Con Isaac Newton questa visione raggiunge una forma compiuta. Nei Principia Mathematica (1687), le stesse equazioni descrivono la caduta dei gravi sulla Terra e il moto dei pianeti nei cieli. È un passaggio concettuale enorme: non solo la natura obbedisce a leggi matematiche, ma queste leggi sono universali. Come scriverà Laplace un secolo dopo, in linea di principio una mente che conoscesse tutte le leggi e le condizioni iniziali potrebbe prevedere l’intero futuro dell’universo (Essai philosophique sur les probabilités, 1814).
Da quel momento in poi, l’idea che comprendere significhi “trovare le equazioni” diventa il cuore della scienza moderna. Dalla termodinamica all’elettromagnetismo, dalla meccanica quantistica alla relatività generale, la matematica non accompagna la fisica: la costituisce.
Resta però una domanda aperta e affascinante, formulata in modo celebre da Eugene Wigner: perché la matematica funziona così bene nel descrivere il mondo? Nel suo saggio The Unreasonable Effectiveness of Mathematics in the Natural Sciences (1960), Wigner parla di un “miracolo” che non sappiamo spiegare del tutto. La matematica è una scoperta o un’invenzione? È il linguaggio della natura o il filtro della mente umana?
Questa fiducia nella matematica non rimane confinata alle scienze naturali. A partire dal XVIII secolo, l’idea che anche i fenomeni sociali ed economici possano obbedire a regolarità formali comincia a prendere piede. Se la natura fisica è governata da leggi, perché non dovrebbero esserlo anche i comportamenti umani quando osservati in aggregato?
Un primo passo in questa direzione è compiuto da Pierre-Simon Laplace e da Adolphe Quetelet. Quest’ultimo, nel XIX secolo, introduce il concetto di “uomo medio” e mostra che fenomeni come criminalità, matrimoni o suicidi presentano una sorprendente stabilità statistica nel tempo (Quetelet, Sur l’homme et le développement de ses facultés, 1835). Per Quetelet, la regolarità dei dati sociali suggerisce l’esistenza di leggi statistiche che governano il comportamento collettivo, anche se le azioni individuali restano libere e imprevedibili.
In economia, la matematizzazione prende forma in modo sistematico tra XIX e XX secolo. Da Cournot a Walras, l’analisi economica viene costruita sempre più esplicitamente come un sistema di equazioni. L’equilibrio generale walrasiano rappresenta un tentativo ambizioso di descrivere l’intero sistema economico come un insieme coerente di relazioni matematiche tra agenti, prezzi e quantità. Lionel Robbins definirà l’economia come la scienza che studia il comportamento umano come relazione tra fini e mezzi scarsi, aprendo la strada a una formalizzazione sempre più rigorosa.
Nel Novecento, questo approccio si consolida. La teoria dei giochi, sviluppata da John von Neumann e Oskar Morgenstern (Theory of Games and Economic Behavior, 1944), applica strumenti matematici sofisticati allo studio delle interazioni strategiche, mostrando come cooperazione, conflitto e istituzioni possano essere analizzati con lo stesso rigore delle leggi fisiche. Più tardi, l’econometria rende possibile il confronto sistematico tra modelli matematici e dati empirici, rafforzando l’idea che i fenomeni economici possano essere spiegati, almeno in parte, attraverso relazioni quantitative.
Naturalmente, la matematica nelle scienze sociali ha uno status diverso rispetto alle scienze naturali. Le “leggi” economiche e sociali sono tipicamente probabilistiche, dipendenti dal contesto istituzionale e storico, e soggette a cambiamento quando gli individui reagiscono ai modelli stessi. Come osservava Keynes, “gli atomi dell’economia non sono come gli atomi della fisica”. Eppure, proprio la matematica consente di rendere esplicite le ipotesi, di chiarire i meccanismi causali e di distinguere ciò che segue logicamente da ciò che è solo intuitivo.
In questo senso, l’estensione della matematica ai fenomeni sociali rappresenta una continuazione naturale della svolta galileiana. Non perché la società sia una macchina governata da leggi rigide, ma perché trattare i comportamenti umani come oggetti di analisi formale permette di individuare regolarità, vincoli e trade-off che altrimenti resterebbero nascosti. Come nelle scienze naturali, la matematica non elimina la complessità del reale, ma offre un modo potente per pensarla.
Forse la risposta sta proprio nella storia di questa idea. L’uomo non ha semplicemente “scoperto” che la natura obbedisce a leggi matematiche in un istante preciso. Ha imparato, gradualmente, che trattare il mondo come se fosse matematicamente ordinato permette di comprenderlo meglio, di prevederne il comportamento e di intervenire su di esso. In questo senso, la matematica non è solo il linguaggio della natura, ma anche una straordinaria estensione delle nostre capacità cognitive.
Ed è proprio questa convergenza tra struttura del mondo e struttura del pensiero che rende la scienza moderna una delle più radicali avventure intellettuali della storia umana.