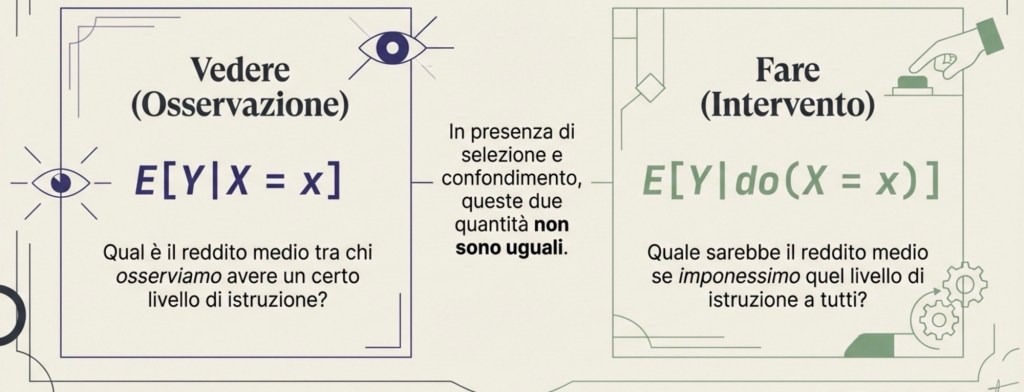
Stai leggendo di c — la lettera che i fisici usano per indicare quella che comunemente chiamiamo “velocità della luce”. Il suo valore misurato è circa 300.000 chilometri al secondo nel vuoto: la velocità con cui un raggio di luce percorre la distanza tra Roma e Tokyo in meno di un centesimo di secondo. È il numero più celebre della fisica moderna, protagonista di equazioni come E=mc². Eppure il nome con cui lo chiamiamo è, come vedremo, profondamente sbagliato.
Chiamare c una “velocità” è come definire il tasso di cambio euro-dollaro “il prezzo di un dollaro”: tecnicamente si può argomentare, ma si perde completamente il punto. c non descrive quanto velocemente la luce attraversa lo spazio. Rappresenta qualcosa di molto più strano e fondamentale: la firma geometrica della realtà in cui viviamo.
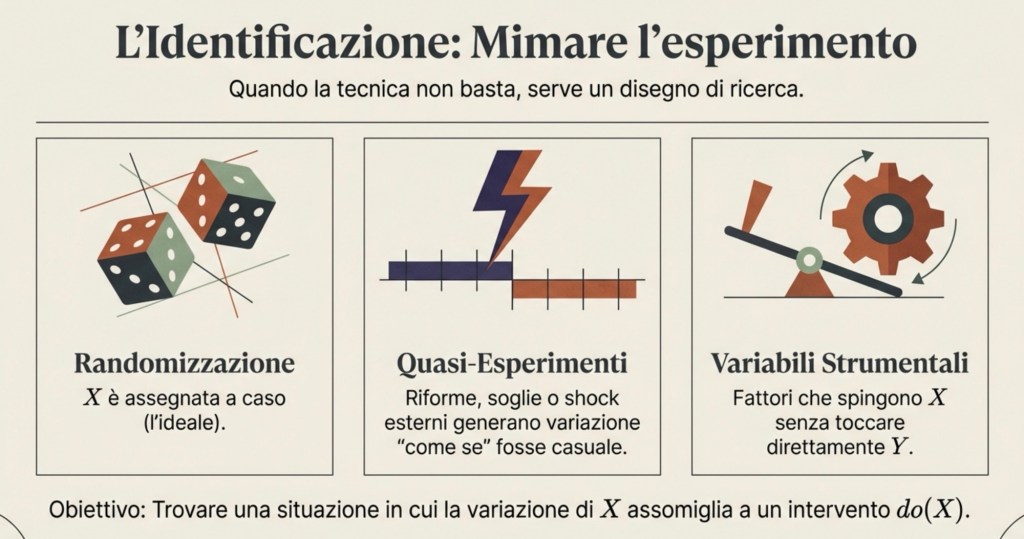
- Il numero che scompare: perché c = 1
Sei abituato a sentire 300.000 km/s come se fosse un dato sacro dell’universo. Non lo è.
Quel numero è un artefatto storico, legato alle unità di misura che gli esseri umani hanno scelto per ragioni pratiche e del tutto arbitrarie. Abbiamo definito il chilometro pensando alla geometria della Terra, e il secondo pensando alla rotazione terrestre. Nessuna delle due scelte ha a che fare con la struttura profonda dell’universo.
Se misurassimo le distanze in miglia, il numero cambierebbe. Se usassimo gli anni-luce per le distanze e gli anni per il tempo, quel numero svanirebbe del tutto: c diventerebbe esattamente 1.
Nei sistemi di unità che i fisici teorici usano per spogliare le equazioni da ogni sovrastruttura umana, c non è un numero grande. È un numero puro, adimensionale, privo di unità di misura. È l’1 dell’universo.
Questo ci dice qualcosa di cruciale: c non è un valore di movimento. È un rapporto di conversione — il numero che permette alla geometria quadridimensionale di funzionare senza l’impiccio delle nostre unità arbitrarie. - Lo spaziotempo: quando spazio e tempo diventano una cosa sola
Per capire cosa sia davvero c, dobbiamo prima fare un passo indietro e chiederci: cos’è lo spaziotempo?
Prima di Einstein, spazio e tempo erano considerati entità separate. Lo spazio era il palcoscenico — tre dimensioni in cui gli oggetti si muovono. Il tempo era qualcosa di diverso, una freccia che scorreva indipendente, uguale per tutti.
Nel 1905 Einstein mostrò che non funziona così. Nel 1908 il matematico Hermann Minkowski formalizzò l’idea in modo rigoroso: spazio e tempo sono dimensioni della stessa struttura, che chiamiamo spaziotempo. Immagina di descrivere la posizione di un evento — diciamo, un fulmine che cade. Non basta dire dove è caduto (latitudine, longitudine, altitudine: tre coordinate spaziali). Devi anche dire quando. Servono quattro coordinate in totale: tre spaziali e una temporale. Lo spaziotempo è quella struttura quadridimensionale.
È qui che entra c. Per sommare una coordinata spaziale (in chilometri) con una coordinata temporale (in secondi) serve un fattore di conversione. Quel fattore è c: stabilisce che un secondo di tempo “equivale” a circa 300.000 km di spazio. Senza c, spazio e tempo parlerebbero lingue diverse e non potrebbero essere unificati. - Il tasso di cambio tra spazio e tempo
Torniamo alla nostra analogia con la valuta.
Quando cambi euro in dollari, usi un tasso di cambio. Quel tasso non è né un euro né un dollaro: è la relazione tra i due. Bene: c fa esattamente la stessa cosa tra spazio e tempo all’interno dello spaziotempo.
Questa equivalenza non è solo una comodità matematica — suggerisce qualcosa di fisicamente profondo: spazio e tempo non sono due sostanze diverse. Sono la stessa entità, percepita diversamente solo perché la nostra biologia ci ha costretti a inventare due parole per descriverla.
Noi ci muoviamo liberamente nelle tre direzioni spaziali. Lungo la dimensione temporale, invece, veniamo trasportati — sempre in avanti, senza controllo. È questa asimmetria cognitiva che ci ha portati a vedere spazio e tempo come cose separate. c è la costante che ricuce questa separazione artificiale. - Il budget di movimento: tutti a velocità c
Eccoti uno dei concetti più vertiginosi della fisica moderna.
Ogni oggetto nell’universo — un fotone, un elettrone, tu in questo momento — si muove attraverso lo spaziotempo a una velocità totale costante, sempre uguale a c. Prima di spiegare perché, vale la pena chiarire cosa sia un fotone: è la particella elementare che costituisce la luce e, più in generale, tutta la radiazione elettromagnetica. Non ha massa — ci torneremo — e questo lo rende un caso limite fondamentale.
Il punto centrale è che questo budget totale di movimento pari a c si distribuisce tra le dimensioni dello spaziotempo. Questa non è un’intuizione magica: deriva direttamente dalla metrica di Minkowski, l’equazione che descrive la “distanza” nello spaziotempo in modo analogo al teorema di Pitagora per lo spazio ordinario. Ma l’immagine è potente e corretta:
∙ Se sei fermo nello spazio, tutto il tuo budget di movimento scorre lungo la dimensione temporale, alla velocità massima possibile. Stai “invecchiando” nel tempo alla velocità c.
∙ Se inizi a muoverti nello spazio, la geometria impone che tu sottragga qualcosa al tuo moto temporale. Risultato: il tuo tempo rallenta. Questo non è un effetto misterioso — è il meccanismo geometrico della dilatazione del tempo, confermato sperimentalmente con orologi a bordo di aerei e satelliti GPS.
∙ Se non hai massa — come un fotone — esaurisci l’intero budget nello spazio, senza lasciare nulla al tempo.
Più vai veloce nello spazio, più lentamente ti muovi nel tempo. Non è una metafora: è geometria. - Perché la luce “viaggia a c”: non è una spinta, è una mancanza
Perché i fotoni si muovono esattamente a c? Non perché qualcosa li spinga. Ma perché non hanno altra scelta.
La massa agisce come un’ancora: trattiene gli oggetti dall’investire tutto il loro budget di moto nelle direzioni spaziali. Pensa a te che corri: più corri veloce, più il tuo orologio biologico rallenta (in misura infinitesimale alle velocità umane, ma il principio vale). La massa è ciò che ti lega parzialmente alla dimensione temporale.
Un fotone non ha massa, quindi non ha nulla che lo trattenga: la geometria stessa lo porta istantaneamente al limite. E poiché esaurisce tutto il suo budget nel moto spaziale, un fotone non possiede più alcun moto nella dimensione temporale. Dal suo “punto di vista” — se un punto di vista potesse esistere per un’entità senza massa — il tempo non scorre. L’universo intero viene attraversato in un istante eterno. Il fotone non invecchia perché ha scambiato tutta la sua esistenza temporale con il movimento nello spazio. - Non un limite di velocità: un’impossibilità geometrica
Si sente spesso dire che c è un “limite cosmico”, come se un poliziotto invisibile impedisse alle cose di andare più veloci. Non funziona così.
Superare c non è vietato — è geometricamente impossibile, nello stesso senso in cui è impossibile disegnare un triangolo con quattro lati. Non esiste nella struttura dello spaziotempo uno spazio per qualcosa che si muova più velocemente di c. Non è una legge che potrebbe essere abrogata con la tecnologia giusta: è la forma stessa della realtà.
Anche i viaggi iperluminali della fantascienza — motori a curvatura, wormhole — non “superano” c. Cercano di aggirare il problema piegando la geometria: rendere vicini due punti che erano lontani. Ma anche qui la fisica mette un limite: tenere aperto un wormhole richiederebbe materia con densità di energia negativa, che non siamo in grado di produrre — e che forse non esiste in forma macroscopica. La geometria permette l’idea; la realtà nega i mezzi. - Un fossile del linguaggio: la geometria di Minkowski
Il nome “velocità della luce” è un fossile storico. Nasce nell’Ottocento, quando James Clerk Maxwell scoprì che la luce si propagava a velocità finita — e la luce era l’unica cosa senza massa che si conoscesse. Il nome rimase, anche quando la comprensione andò ben oltre.
Se Maxwell non avesse mai lavorato sull’elettromagnetismo, c esisterebbe comunque: è la costante della geometria di Minkowski, la struttura quadridimensionale che governa lo spaziotempo.
Questa geometria ha una simmetria fondamentale chiamata invarianza di Lorentz. Cosa significa? In fisica, una simmetria è una trasformazione che lascia le leggi invariate. L’invarianza di Lorentz garantisce che le leggi della fisica appaiano identiche per qualunque osservatore, indipendentemente dal suo moto — che tu sia fermo su una panchina o dentro un treno ad alta velocità, le stesse equazioni valgono. c è il numero che rende possibile questa simmetria: è la costante che compare nelle trasformazioni di Lorentz e che rimane uguale per tutti gli osservatori. Proprio questo — il fatto che la velocità della luce sia la stessa in tutti i sistemi di riferimento — fu il punto di partenza sperimentale di Einstein nel 1905.
In questa prospettiva, la contrazione di Lorentz — il fatto che gli oggetti in moto appaiano più corti — non è una compressione fisica: è una rotazione geometrica nello spaziotempo, analoga a come un oggetto ruotato nello spazio ordinario sembra più corto se visto di lato.
E la celebre E = mc² non riguarda la luce: afferma che energia e massa sono la stessa grandezza espressa in unità diverse, con c² che funge da fattore di conversione tra joule e chilogrammi. La luce, in quella formula, è un ospite illustre ma non il protagonista.
Conclusione: l’impronta digitale dell’universo
In ultima analisi, c è il numero che definisce in quale tipo di geometria viviamo. Non è un limite imposto dall’ingegneria — è la forma stessa della realtà.
Resta però una domanda aperta, e onestamente affascinante: perché c ha proprio quel valore? Perché 300.000 km/s e non il doppio? Se il valore fosse diverso, gli atomi cambierebbero dimensione, le stelle brucerebbero in modo diverso, la vita come la conosciamo svanirebbe. Alcuni fisici, nel contesto della Teoria delle Stringhe, suggeriscono che il nostro universo sia solo uno dei moltissimi possibili, e che abbia questa particolare firma geometrica per ragioni statistiche — quella che si chiama selezione antropica: siamo qui a fare questa domanda proprio perché il valore di c è compatibile con la nostra esistenza. Altri sperano in una teoria più profonda, in cui c non sia un dato di partenza arbitrario ma un risultato inevitabile.
Non lo sappiamo ancora.
Quello che sappiamo è che noi — tu, io, ogni atomo del tuo corpo — siamo processi interamente costituiti da questa costante. Non siamo osservatori di c: siamo geometria in movimento, indissolubilmente legati al numero che dice allo spazio quanto vale nel tempo.
Modifiche rispetto alla versione precedente: introdotta la definizione di c nella prima sezione; aggiunta sezione dedicata allo spaziotempo (sezione 2, prima della valuta); definito il fotone nel punto in cui compare; spiegata la metrica di Minkowski come base del “budget di movimento”; chiarito il significato di invarianza di Lorentz e simmetria; aggiunta la selezione antropica in conclusione.